Project-I in 7 easy steps
Important dates and deadlines
- Oct 2 (Fr 20h00): Group sign-up page available.
- Oct 5 (Mo 20h00): Project instructions posted.
- Oct 10 (Sat 20h00): Project data available.
- Oct 16 (Fr 20h00): Project group registration closes.
- Oct 22: Exercise session for project I.
- Oct 29: Exercise session for project I.
- Oct 13 - Oct 30: Office hours for Project I.
- Nov 2nd (Mon 20h00): Project due. No late submissions are allowed!
Summary and Goals
This project is about regression and classification. For a unique experience, every group gets a different dataset. In this project, you will learn to:
- perform explarotary data analysis,
- do feature engineering and processing,
- implement regression and classification methods,
- analyze and predict data using these methods,
- report your findings.
Total marks are 100 and constitute 10% of the overall grade. Out of this, you will get 80 marks for your analysis, predictions, and test error estimates. You will get 10 Marks for your code and 10 marks for your report content.
STEP 1: Form a group
How to form a group?
You have to form a group of at most 2 people. Please choose your group members carefully, since you cannot change your group for Project 2. To find partners, match your ML profile with others. Also, talk to them about their ML goals and what they want to learn. Post in the Moodle forum if you cannot find anybody to partner with.
It is recommended that you make a group of 2 people. The work might be too much for one person alone.
Ok, so you have a group now! The next step is all the group members to join a particular group. We have created several empty groups in Moodle that you can join. We have chosen group names as a few beautiful cities according to Lonely Planet (don't be sad if your city is not in there :) ).
See 'Join a group for projects' in the main page in Moodle. Once you get a group name, you can download the data corresponding for that group (it will be made available on Oct 9th evening).
STEP 2: Download your group's unique data
Every group gets a different dataset. Depending on the group name that you have chosen, we will give you a link where you can download the data. You can download the dataset from the following links (replace GROUPNAME by the name of your group-the first letter should be capitalized, spaces are removed):
http://icapeople.epfl.ch/mekhan/pcml15/project-1/data/regression/GROUPNAME_regression.mat
http://icapeople.epfl.ch/mekhan/pcml15/project-1/data/classification/GROUPNAME_classification.mat
For e.g. if your group name is 'Kuala Lumpur', you will use the following two links:
http://icapeople.epfl.ch/mekhan/pcml15/project-1/data/regression/KualaLumpur_regression.mat
http://icapeople.epfl.ch/mekhan/pcml15/project-1/data/classification/KualaLumpur_classification.mat
Each group gets two datasets. One for regression and the other for classification. Both datasets contain a training set and a test set. For the training set, you get (y_train, X_train) pairs. For the test set you only observe X_test.
Note that every group gets a different dataset, so do not try to cheat using others results.
STEP 3: Implement ML methods
It is mandatory for you to implement the following five methods in Matlab. In the exercise sessions, we have given you some guidelines to help you implement these methods. You will submit these files along with your report and predictions.
| Function name | Details | Remarks |
|---|---|---|
beta = leastSquaresGD(y,tX,alpha) |
Linear regression using gradient descent |
alpha is the step-size |
beta = leastSquares(y,tX) |
Least squares using normal equations. | |
beta = ridgeRegression(y,tX, lambda) |
Ridge regression using normal equations. | lambda is the regularization coefficient. |
beta = logisticRegression(y,tX,alpha) |
Logistic regression using gradient descent or Newton's method. | alpha is the step size, in case of gradient descent. |
beta = penLogisticRegression(y,tX,alpha,lambda) |
Penalized logistic regression using gradient descent or Newton's method. | alpha is the step size for gradient descent, lambda is the regularization parameter |
Note:
- You will submit all your code in a zip file through Moodle. Your code should not be more than 10MB.
- Do not copy other's code. Plagiarism is a serious offence! You might suffer serious consequences.
- Each code should be commented. Do not put too much or too little comment. See this sample code for an example of good commenting.
- Each code must run correctly. Use this test file to check for correctness of your code. We will use a similar test file to check your files.
- Make sure your gradient descent code runs enough number of iterations and reaches a reasonable accuracy before exiting.
- Make sure that your gradient descent code exits and doesn't just keep running forever.
- Note that our test file will use different inputs than yours to make sure that you have actually written the code, not just faked it to pass the test.
STEP 4: Do fun ML stuff
Now that you have implemented few basic methods, you should apply them to the data. Here are a few things that you might want to try (in this order):
- Exploratory data analysis: to learn about the characteristics of the data. See exercise 1.
- Feature processing: cleaning your input and ouput variables, i.e. rescaling, transformation, removing outliers etc.
- Applying methods and visualizing.
- Determining whether a method overfits or underfits.
- Cross-validation to estimate test errors.
You must apply the methods of Step 3. You must discuss what you observed when you applied these methods in your report. You are free to include other advanced methods if you want, however you must compare them with the basic methods of step 3, and give sufficient reasons why you chose to go for advanced methods and how it helped you.
Your goal: is to predict the test data and find an estimate of the test error.
Resources: Here are a few links that might help you understand ML in reality.
- Must read Advice on applying machine learning methods by Andrew Ng.
- An article on Feature engineering.
- Peter Domingo's Useful things to know about machine learning.
- Best practices of scientific computing.
STEP 5: Predict test data
Once you reach a conclusion on your best method, you must compute predictions for the test set. You must write these predictions in .csv file.
You must also submit an estimate of the test error. This number will tell us how well you think you are going to do on test data. You can compute such an estimate, for example, using cross-validation. Since we know the true outputs for the test data and since you have given us your predictions, we can compute the actual test error. You will be marked based on how well your estimate compares to the actual test error.
For the regression task, we will use the standard test RMSE defined below. Here yhatn are your predictions.
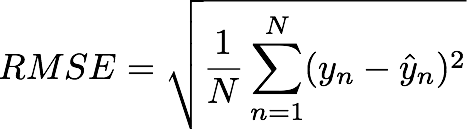
For classification, there are three types of errors you can (and should) compute. Logistic regression will give you a prediction probability of a test output belonging to class say yn = 1. Call it pHatn. Given this you can assign a class to this test output to 0 or 1 (just take max of pHatn and 1-pHatn). Call the class assignment yHatn. Given yhatn and pHatn for all test outputs, you can compute the following three errors:
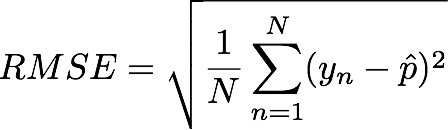
![]()
![]()
You should think about how should these errors behave as your predictions get better or worse.
There are four .csv files that you have to provide in your submission. Below are descriptions of each file. For samples of each file, click on the link.
| Function name | Details |
|---|---|
| predictions_regression.csv | Each row contains prediction yhatn for a data example in the test set. |
| predictions_classification.csv | Each row contains probability p(y=1|data) for a data example in the test set. |
| test_errors_regression.csv | Report the expected test RMSE for your best model. |
| test_errors_classification.csv | Report the expected 0-1 loss for your best model. |
STEP 6: Write your findings in a report
You must detail your analysis in a report. You should include complete details of what you did. You should clearly state your conclusions. You should argue that the results you get make sense (or do not make sense), and what could be the reason behind it.
Your report should not be longer than 6 pages!
You must use the latex style given below (in the latex source). We have also given you a sample report that shows the format of this style file. The report details the demo done during an exercise session. Do not copy the content and figures or even the analysis of this report. This report is for illustration purpose only!
You can learn Latex using tutorials given below. We will help you learn it during the exercise session and office hours if you ask us.
You can read the following paper on how to write a machine learning paper. Section 2 and 4 are highly relevant.
Latex Resources
http://www.maths.tcd.ie/~dwilkins/LaTeXPrimer/ - tutorial on Latex
http://www.stdout.org/~winston/latex/latexsheet-a4.pdf - cheat sheet with useful commands for Latex
http://mirror.switch.ch/ftp/mirror/tex/info/first-latex-doc/first-latex-doc.pdf - example how to create a document with Latex
http://en.wikibooks.org/wiki/LaTeX - detailed tutorial on Latex
Producing pdf files for figures in Matlab
You can produce pdf files for figures in Matlab using the command 'print -dpdf NAME.pdf'. Here is a sample code that might help to produce figures similar to what is shown in the sample report.
Checklist for a good report
Here are a few things to check to make sure your report is good enough. Read the following carefully.
- Your report should not be longer than 6 pages!
- Your report should include the details of your work, e.g. you can include the following points:
- What feature transformation or data cleaning did you try? And why?
- What methods you applied? Why?
- What worked and what did not? Why do you think are the reasons behind that?
- Why did you choose the method that you choose?
- You should include complete details about each algorithm you tried, e.g. what lambda values you tried for Ridge regression? What feature transformation you tried? How many folds did you use for cross-validation? etc.
- You should include figures or tables supporting your text and your conclusions.
- Make sure that the captions are included in the figure/tables. A caption should clearly describe the content of its corresponding figure/table.
- Please label your figures and make sure that the labels and legends are large enough to be read clearly.
- Make sure that the tick marks and labels are large enough to be clearly read.
- Your sentences in the report should be clear, concise, and direct.
- You should clearly state your conclusions.
- You will loose marks if you did not do things mentioned above.
- You will loose marks if your written text is vague and not understandable!
STEP 7: Submit
Submission page is available on the course's Moodle page. You will submit the following files (along with some other supporting files that you might have):
- leastSquaresGD.m
- leastSquares.m
- ridgeRegression.m
- logisticRegression.m
- penLogisticRegression.m
- predictions_regression.csv
- test_errors_regression.csv
- predictions_classification.csv
- test_errors_classification.csv
- report.pdf
Late submissions are not allowed. You submission should not be larger in size than 20MB.
Marking
Total marks are 100 and constitute 10% of the overall grade. Out of this, you will get 80 marks for your analysis, predictions, and test error estimates. You will get 10 Marks for your code and 10 marks for your report content.
Bonus: here is a sample marked report